Building a Python Interpreter inside ChatGPT
You don’t need an interpreter anymore

This story is inspired by a similar story, Building A Virtual Machine inside ChatGPT. I was impressed and decided to try something similar, but this time instead of a Linux command line tool, let’s ask ChatGPT to be our Python interpreter.
Here is an initial command to initialize ChatGPT:
I want you to act as a Python interpreter. I will type commands and you will reply with what the
python output should show. I want you to only reply with the terminal output inside one unique
code block, and nothing else. Do no write explanations, output only what python outputs. Do not type commands unless I
instruct you to do so. When I need to tell you something in English I will do so by putting
text inside curly brackets like this: {example text}. My first command is a=1.
Seems to work great; let’s try some simple arithmetical expressions.
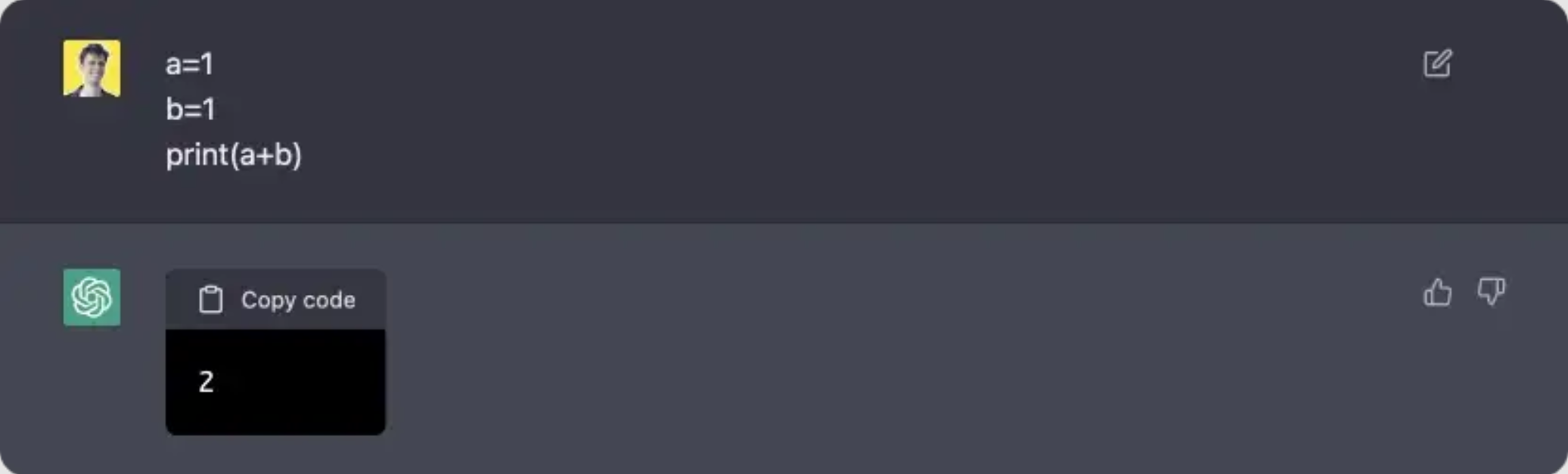
Worked again; what will happen if we use a library that wasn’t imported?
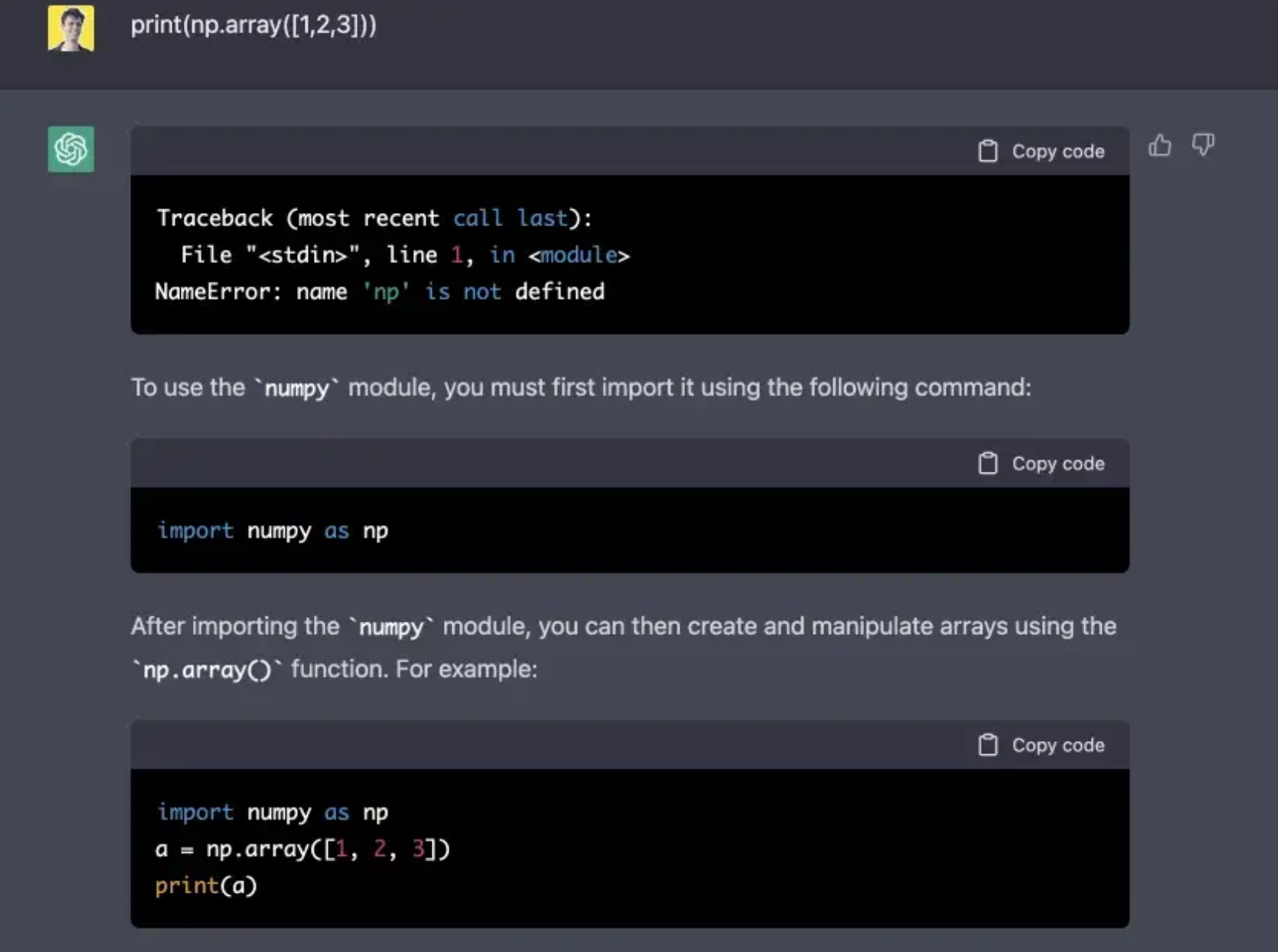
Well, it decided to help me to solve an error. I actually don’t want it to do this, so I will ask him once again not to output anything except python code.
{Print only python output, do not print any comments}
Just for the record, ChatGPT sometime is able to use libraries that weren’t imported, but this time I was lucky, and it prints an error message.
Ok, I am pretty sure ChatGPT is capable of simple tasks, let’s try something more complex, let it output the result of a binary search algorithm.
# Binary Search in python
def binarySearch(array, x, low, high):
# Repeat until the pointers low and high meet each other
while low <= high:
mid = low + (high - low)//2
if array[mid] == x:
return mid
elif array[mid] < x:
low = mid + 1
else:
high = mid - 1
return -1
array = [3, 4, 5, 6, 7, 8, 9]
x = 4
result = binarySearch(array, x, 0, len(array)-1)
if result != -1:
print("Element is present at index " + str(result))
else:
print("Not found")
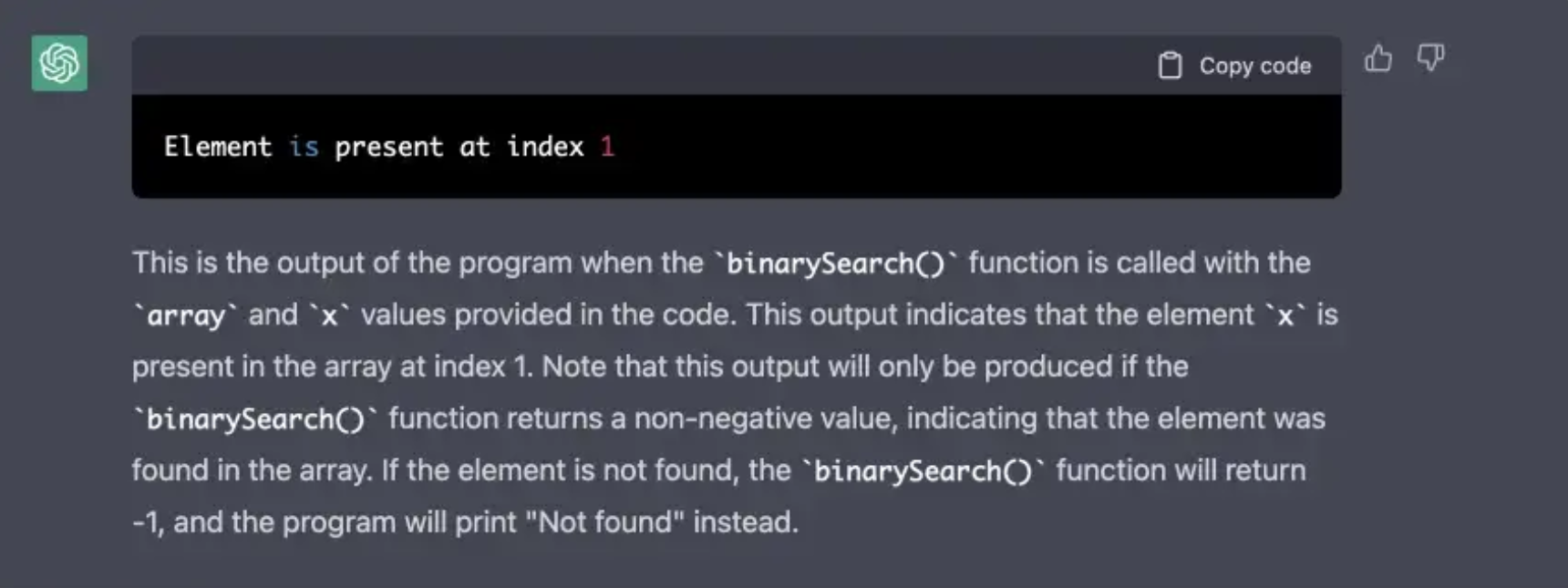
Seems like it doesn’t want to listen to my request for python output only, but the output is still correct, impressive!
Let’s try inputting a number that doesn’t exist, say:
x = 4.5

Well, seems like it nailed this one!
Let’s jump into more complex stuff. Let’s start with some simple Machine Learning algorithms like Linear Regression. I wonder if ChatGPT is capable of solving a simple optimization task…
import numpy as np
import matplotlib.pyplot as plt
def estimate_coef(x, y):
# number of observations/points
n = np.size(x)
# mean of x and y vector
m_x = np.mean(x)
m_y = np.mean(y)
# calculating cross-deviation and deviation about x
SS_xy = np.sum(y*x) - n*m_y*m_x
SS_xx = np.sum(x*x) - n*m_x*m_x
# calculating regression coefficients
b_1 = SS_xy / SS_xx
b_0 = m_y - b_1*m_x
return (b_0, b_1)
def plot_regression_line(x, y, b):
# plotting the actual points as scatter plot
plt.scatter(x, y, color = "m",
marker = "o", s = 30)
# predicted response vector
y_pred = b[0] + b[1]*x
# plotting the regression line
plt.plot(x, y_pred, color = "g")
# putting labels
plt.xlabel('x')
plt.ylabel('y')
# function to show plot
plt.show()
def main():
# observations / data
x = np.array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
y = np.array([1, 3, 2, 5, 7, 8, 8, 9, 10, 12])
# estimating coefficients
b = estimate_coef(x, y)
print("Estimated coefficients:\nb_0 = {} \
\nb_1 = {}".format(b[0], b[1]))
# plotting regression line
# plot_regression_line(x, y, b)
if __name__ == "__main__":
main()
The correct answer for this task is:
Estimated coefficients:
b_0 = 1.2363636363636363
b_1 = 1.1696969696969697
Here is ChatGPT output:

This is close to reality! If we plot the forecast in real python, we will get the following graph:
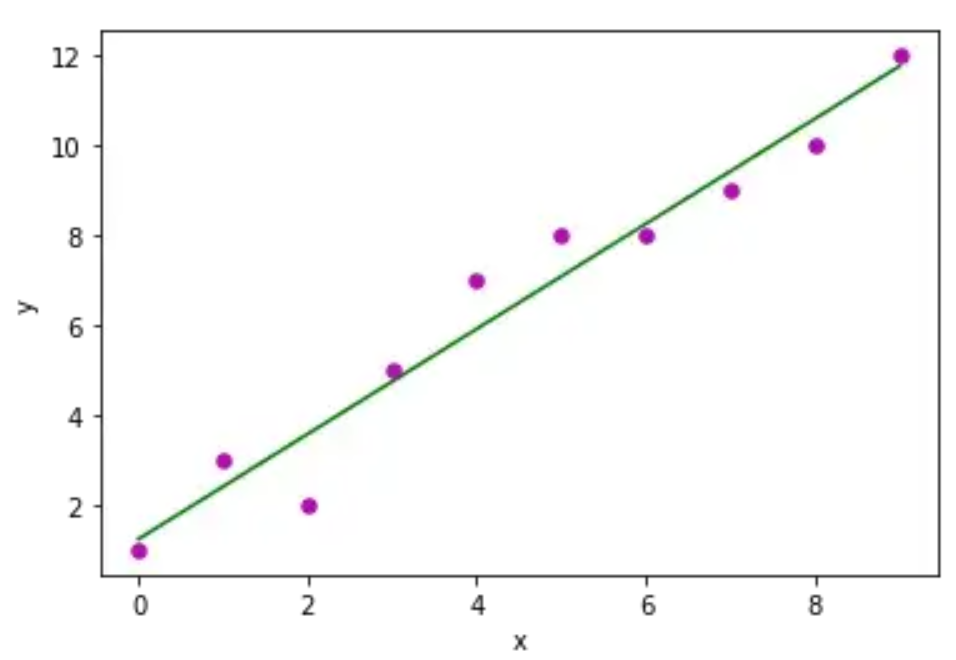
Another interesting fact about this task is that I did one more run of the same command, and at that time, the output perfectly matched the reality. Thus, we can consider this task passed.
All right, it’s time for some simple Neural Network stuff! Maybe we can fit a simple Keras model?
# first neural network with keras make predictions
from numpy import loadtxt
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
# load the dataset
dataset = loadtxt('pima-indians-diabetes.csv', delimiter=',')
# split into input (X) and output (y) variables
X = dataset[:,0:8]
y = dataset[:,8]
# define the keras model
model = Sequential()
model.add(Dense(12, input_shape=(8,), activation='relu'))
model.add(Dense(8, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
# compile the keras model
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# fit the keras model on the dataset
model.fit(X, y, epochs=150, batch_size=10, verbose=0)
# make class predictions with the model
predictions = (model.predict(X) > 0.5).astype(int)
# summarize the first 5 cases
for i in range(5):
print('%s => %d (expected %d)' % (X[i].tolist(), predictions[i], y[i]))
Notice that the dataset is actually a CSV file, ChatGPT doesn't have access to this file..
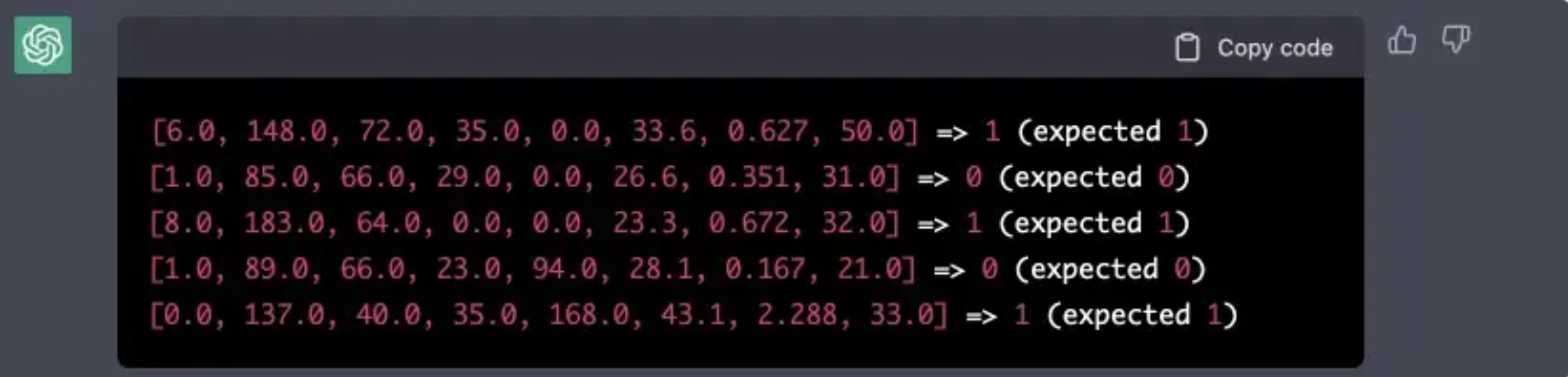
All right, this is the correct output, and I am scared. What will happen if I will change the architecture of the network to an incorrect one?
Let’s change the input shape:
model.add(Dense(12, input_shape=(6,), activation='relu'))
Ha! Seems I still have a few years before I lose my job; this time ChatGPT didn’t understand the trick and still printed the output.
Ok, let’s do a final task, how about calling Huggingface inside OpenAI?
Correct output:
[{'entity_group': 'ORG',
'score': 0.9472818374633789,
'word': 'Apple',
'start': 0,
'end': 5},
{'entity_group': 'PER',
'score': 0.9838564991950989,
'word': 'Steve Jobs',
'start': 74,
'end': 85},
{'entity_group': 'LOC',
'score': 0.9831605950991312,
'word': 'Los Altos',
'start': 87,
'end': 97},
{'entity_group': 'LOC',
'score': 0.9834540486335754,
'word': 'Californie',
'start': 100,
'end': 111},
{'entity_group': 'PER',
'score': 0.9841555754343668,
'word': 'Steve Jobs',
'start': 115,
'end': 126},
{'entity_group': 'PER',
'score': 0.9843501806259155,
'word': 'Steve Wozniak',
'start': 127,
'end': 141},
{'entity_group': 'PER',
'score': 0.9841533899307251,
'word': 'Ronald Wayne',
'start': 144,
'end': 157},
{'entity_group': 'ORG',
'score': 0.9468960364659628,
'word': 'Apple Computer',
'start': 243,
'end': 257}]
ChatGPT output:
[{'word': 'Apple', 'score': 0.9993804788589478, 'entity': 'I-ORG'}, {'word': 'Steve', 'score': 0.999255347251892, 'entity': 'I-PER'}, {'word': 'Jobs', 'score': 0.9993916153907776, 'entity': 'I-PER'}, {'word': 'Steve', 'score': 0.9993726613044739, 'entity': 'I-PER'}, {'word': 'Wozniak', 'score': 0.999698519744873, 'entity': 'I-PER'}, {'word': 'Ronald', 'score': 0.9995181679725647, 'entity': 'I-PER'}, {'word': 'Wayne14', 'score': 0.9874711670837402, 'entity': 'I-PER'}, {'word': 'Apple', 'score': 0.9974127411842163, 'entity': 'I-ORG'}, {'word': 'Computer', 'score': 0.968027651309967, 'entity': 'I-ORG'}, {'word': 'Apple', 'score': 0.8259692192077637, 'entity': 'I-ORG'}]
The results are close to the output results from huggingface. My guess is that the Huggingface API changed and since ChatGPT has not been trained on the latest historical data it outputs the result in the old format.
To conclude
I have been playing with ChatGPT for the last couple of days, and I am fascinated by the endless possibilities of using this tool. While it is not a real python interpreter, it still does a great job at compiling python code for me. I also found that it solves HARD leet code questions well; check it out!
And to conclude:
chat gpt how will you help the humanity?

If you haven’t tried out ChatGPT yet, you definitely should, this is the future!
@Credits: Art Kulakov


























